
Most organizations that claim to be "AI-ready" are usually describing the state of their infrastructure. They mean their data pipelines are clean, automated, and performant. Tables are normalized, freshness SLAs are consistently met, and quality checks pass with flying colors.
And yet, when GenAI systems are put in front of real users, trust breaks almost immediately.
The problem is rarely data hygiene. The problem is that the data isn’t understood.
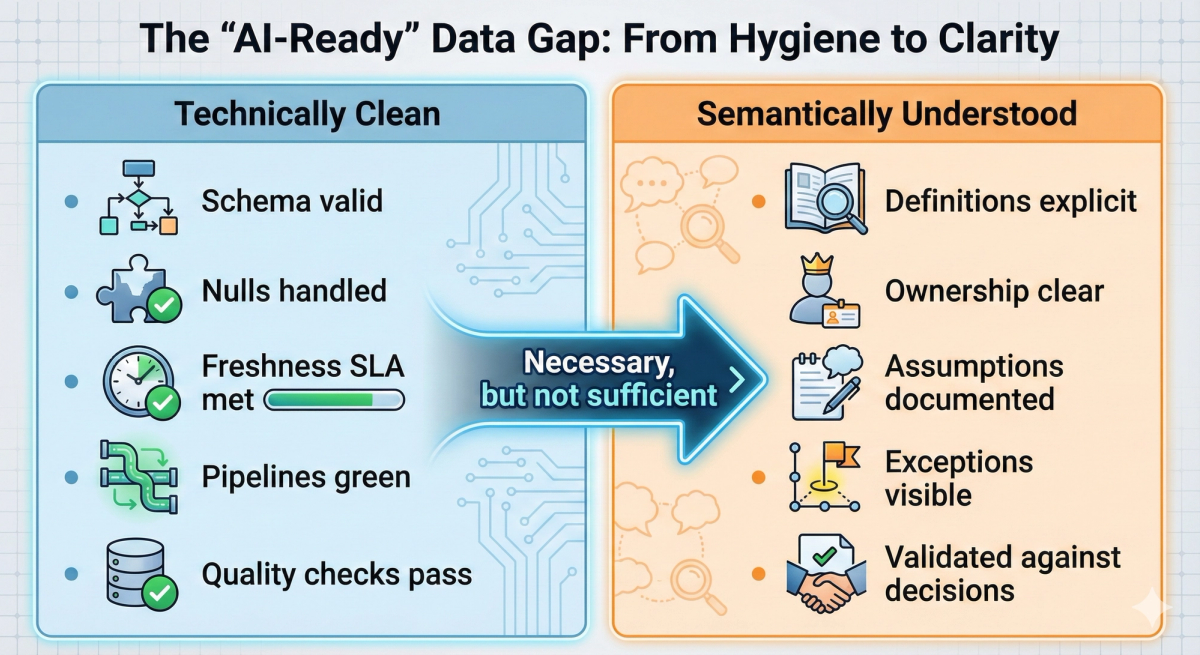
Clean Data vs. Understood Data
We need to decouple technical correctness from semantic clarity.
"Clean" data answers technical questions:
- Does it conform to the schema?
- Are nulls handled correctly?
- Are data types consistent?
- Is the data arriving on time?
These are necessary conditions, but they are not sufficient.
GenAI systems don’t just consume data—they reason over it. This means they implicitly rely on definitions, assumptions, business intent, and exception handling. If those elements are unclear, undocumented, or inconsistent, the model doesn’t fail fast. It fails confidently.
The Uncomfortable Truth: Data can be technically correct and still be semantically wrong. GenAI simply amplifies that gap.
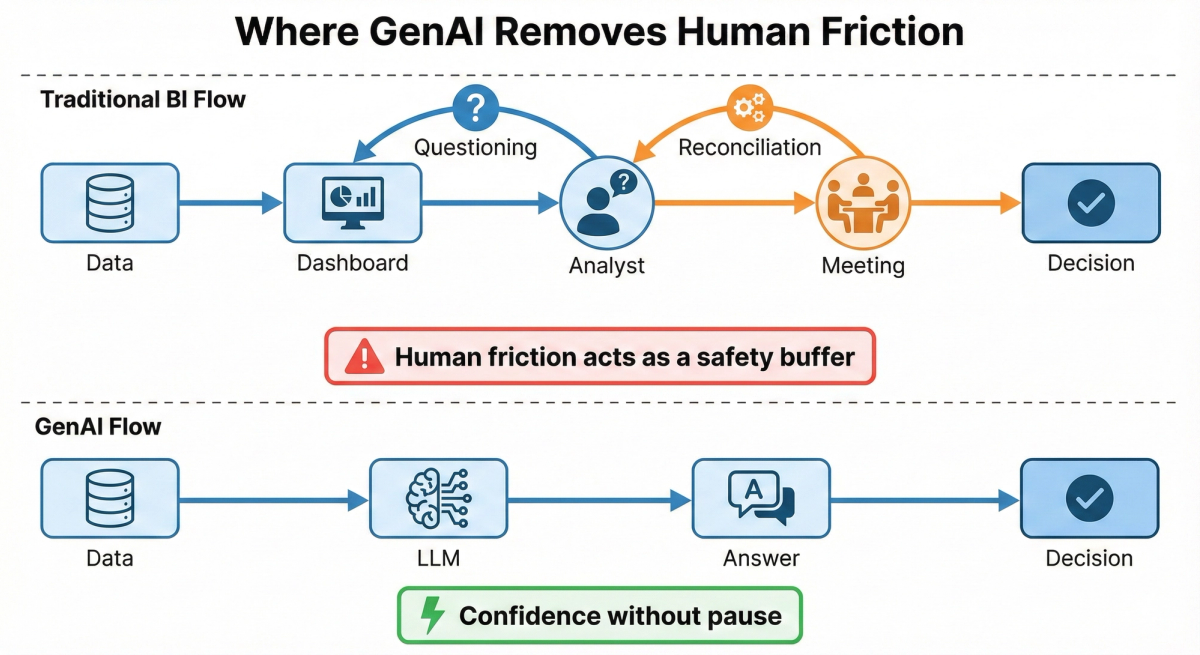
Why This Shows Up First in GenAI
Traditional analytics systems have human friction built into the process. In a standard BI workflow, a wrong dashboard number might be:
- Questioned by a skeptical analyst.
- Reconciled during a prep meeting.
- Explained away as "a known issue" regarding that specific data source.
GenAI removes that friction.
When an executive asks a question in natural language, the system answers instantly and with authority. There is no pause to ask:
- “Which definition of 'churn' did you intend?”
- “Is this number contractual revenue or operational revenue?”
- “Is the logic behind this column still valid after the merger?”
Unless explicitly designed to do so, the model cannot ask clarifying questions. It assumes the data it sees represents absolute reality. That is where the risk lies.
The Semantic Drift Problem
Most organizations do not possess a single, holy grail definition of a metric. They have several: Finance’s version of revenue, Sales’ version of revenue, and Operations’ version of revenue.
Over time, these definitions drift—often subtly, and often for valid business reasons. In traditional reporting, this drift is painful but contained. In GenAI systems, drift becomes dangerous.
The RAG Trap
This danger is acute in systems using RAG (Retrieval-Augmented Generation). RAG mechanisms are based on similarity, not truth.
They retrieve:
- What looks relevant.
- What is closest in the embedding space.
- What happens to be indexed first.
They do not inherently retrieve:
- The currently approved definition.
- The version with business sign-off.
- The logic that survived the last reorg.
When definitions drift, RAG doesn’t surface the disagreement. It arbitrarily chooses a version and presents it as fact. This is the primary reason many GenAI pilots look impressive in controlled demos but become unreliable in production environments.
"AI-Ready" Often Means "Undocumented Logic"
In data migration work, we often find "logic rot": SQL buried in report definitions, hard-coded thresholds in pipelines, or exception handling added years ago that was never revisited.
GenAI doesn’t remove this logic; it inherits it.
If your data platform cannot answer why a calculation exists, who owns it, or when it was last validated, then your AI system cannot answer those questions either. The difference is that humans hesitate when they are unsure. Models do not.
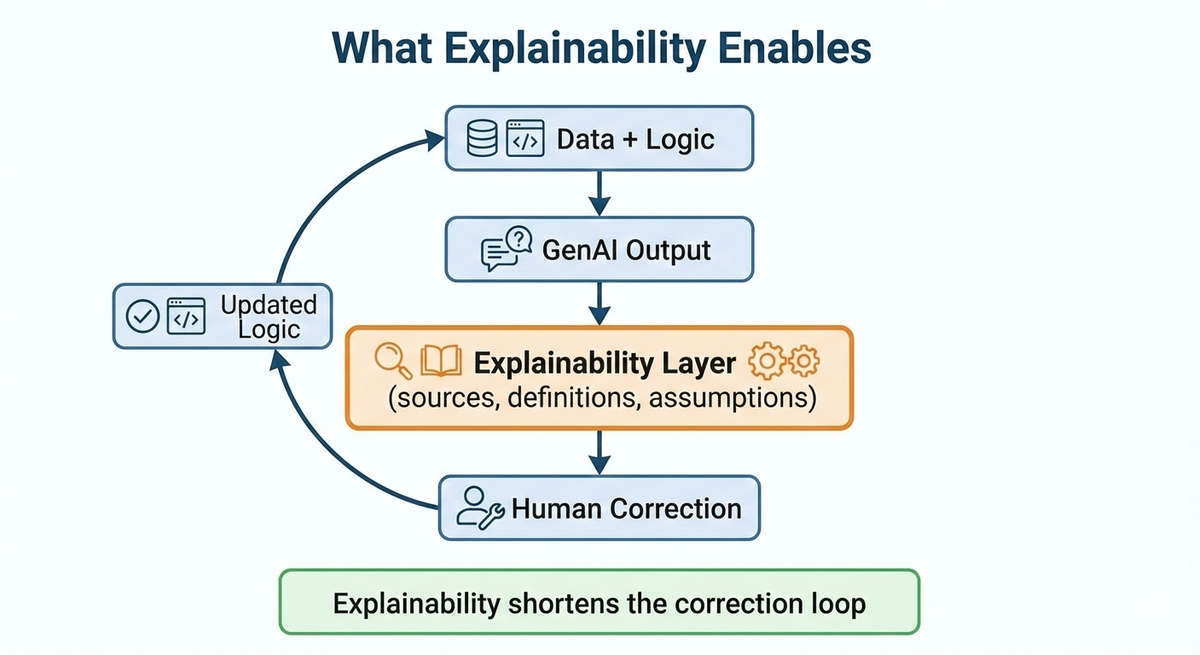
Explainability Is Not an Ethics Feature — It’s a Reliability Requirement
Explainability is often discussed in the context of ethics or regulatory compliance. While valid, that framing is incomplete. In practice, explainability is the only thing that allows systems to be corrected.
An explainable system can answer:
- “Which data sources contributed to this answer?”
- “Which definition was applied?”
- “Which assumptions were made?”
Without that trail, every incorrect output becomes a philosophical debate rather than a technical fix. And debates don’t scale.
Explainability reduces risk because:
- It shortens feedback loops.
- It makes disagreement visible.
- It allows humans to intervene before trust collapses.
What "AI-Ready" Actually Looks Like
AI-ready data is not just clean. It is legible.
That means:
- Definitions are explicit and versioned.
- Ownership of meaning is clear.
- Assumptions are documented, not tribal.
- Validation happens before users complain.
In other words, the system can explain itself—not in marketing language, but in operational terms.
The Migration Lesson GenAI Is Repeating
This pattern isn’t new. Data migrations taught us this lesson years ago. Systems rarely fail because the platform is wrong; they fail because meaning was carried forward without being revisited.
GenAI simply compresses the timeline. What used to take a year of quiet trust erosion now breaks in weeks.
Closing: A Simple Test
If you want to know whether your data is truly AI-ready, ask one question:
Can your teams explain why a number exists—not just where it comes from?
- If the answer is yes, GenAI will amplify your capabilities.
- If the answer is no, GenAI will amplify your confusion.
Clean data makes systems run. Understood data makes them trustworthy. And trust is the real bottleneck to AI at scale.