Impala → BigQuery migration
Move Impala workloads (Hive-compatible SQL, Parquet/ORC tables, partitioned datasets, and UDF-dependent queries) to BigQuery with predictable conversion and verified parity. We prioritize data type mapping, semantic correctness, and validation and reconciliation so cutover decisions are backed by evidence—not assumptions.
- Scope
- Query and schema conversion
- Semantic and type alignment
- Validation and cutover readiness
- Risk areas
- Type & CAST semantics drift
- Function differences and gaps
- Partition model mismatch
- Deliverables
- Prioritized execution plan
- Parity evidence and variance log
- Rollback-ready cutover criteria
Is this migration right for you?
- You have hundreds or thousands of Impala queries
- Business logic lives in SQL, UDFs, or BI queries
- You require provable parity before cutover
- Multiple downstream consumers (BI, ML, exports) depend on correctness
- You are doing a one-time table copy
- There is no semantic dependency on existing queries
- You do not need reconciliation or rollback guarantees
What breaks in an Impala → BigQuery migration
- Type & CAST semantics drift
DECIMAL precision/scale, TIMESTAMP nuances, and implicit casts can produce silent changes in results. Mitigation: explicit data type mapping decisions plus automated cast normalization and parity tests.
- Function differences and gaps
String, date/time, regex, and conditional functions look similar but behave differently across engines. Mitigation: function-by-function rewrites with flagged exceptions and “golden query” result checks.
- Partition model mismatch
mpala partitions (often directory-based) don’t map 1:1 to BigQuery partitioned tables. Mitigation: partitioning design up front (ingestion-time vs query-time), plus clustering where it improves pruning.
- NULL behavior edge cases
NULL comparisons, anti-joins, and predicate pushdown assumptions can change outputs—especially in multi-join analytics. Mitigation: rewrite patterns for NULL-safe logic and validate with targeted edge-case datasets.
- UDF/UDAF portability
Java-based Impala UDF/UDAFs do not “lift and shift” into BigQuery. Mitigation: choose a UDF strategy (rewrite in SQL, use remote UDFs where appropriate, or precompute/reshape data).
- DDL & storage assumptions
Impala external table definitions and location-based patterns do not carry over directly. Mitigation: translate DDL intent (schema + constraints + partition strategy) and formalize ingestion into BigQuery-managed tables.
- Window and analytic function nuances
Default ordering, ties, and frame definitions can differ; this often shows up in ranking, sessionization, and incremental reporting queries. Mitigation: enforce explicit frames/order clauses and validate using known “golden” report outputs.
- Performance regressions from scan patterns
Queries that were acceptable in Impala can become expensive in BigQuery if they scan too broadly or explode row counts. Mitigation: bytes-scanned hygiene (selectivity, pruning), plus clustering/materialization patterns.
- CTE and subquery rewrites
Complex nested queries may need structural rewrites for BigQuery optimization and readability. Mitigation: rewrite to stable patterns, validate outputs, then tune.
| Breakage | Mitigation |
|---|---|
Type & CAST semantics drift DECIMAL precision/scale, TIMESTAMP nuances, and implicit casts can produce silent changes in results. | explicit data type mapping decisions plus automated cast normalization and parity tests. |
Function differences and gaps String, date/time, regex, and conditional functions look similar but behave differently across engines. | function-by-function rewrites with flagged exceptions and “golden query” result checks. |
Partition model mismatch mpala partitions (often directory-based) don’t map 1:1 to BigQuery partitioned tables. | partitioning design up front (ingestion-time vs query-time), plus clustering where it improves pruning. |
NULL behavior edge cases NULL comparisons, anti-joins, and predicate pushdown assumptions can change outputs—especially in multi-join analytics. | rewrite patterns for NULL-safe logic and validate with targeted edge-case datasets. |
UDF/UDAF portability Java-based Impala UDF/UDAFs do not “lift and shift” into BigQuery. | choose a UDF strategy (rewrite in SQL, use remote UDFs where appropriate, or precompute/reshape data). |
DDL & storage assumptions Impala external table definitions and location-based patterns do not carry over directly. | translate DDL intent (schema + constraints + partition strategy) and formalize ingestion into BigQuery-managed tables. |
Window and analytic function nuances Default ordering, ties, and frame definitions can differ; this often shows up in ranking, sessionization, and incremental reporting queries. | enforce explicit frames/order clauses and validate using known “golden” report outputs. |
Performance regressions from scan patterns Queries that were acceptable in Impala can become expensive in BigQuery if they scan too broadly or explode row counts. | bytes-scanned hygiene (selectivity, pruning), plus clustering/materialization patterns. |
CTE and subquery rewrites Complex nested queries may need structural rewrites for BigQuery optimization and readability. | rewrite to stable patterns, validate outputs, then tune. |
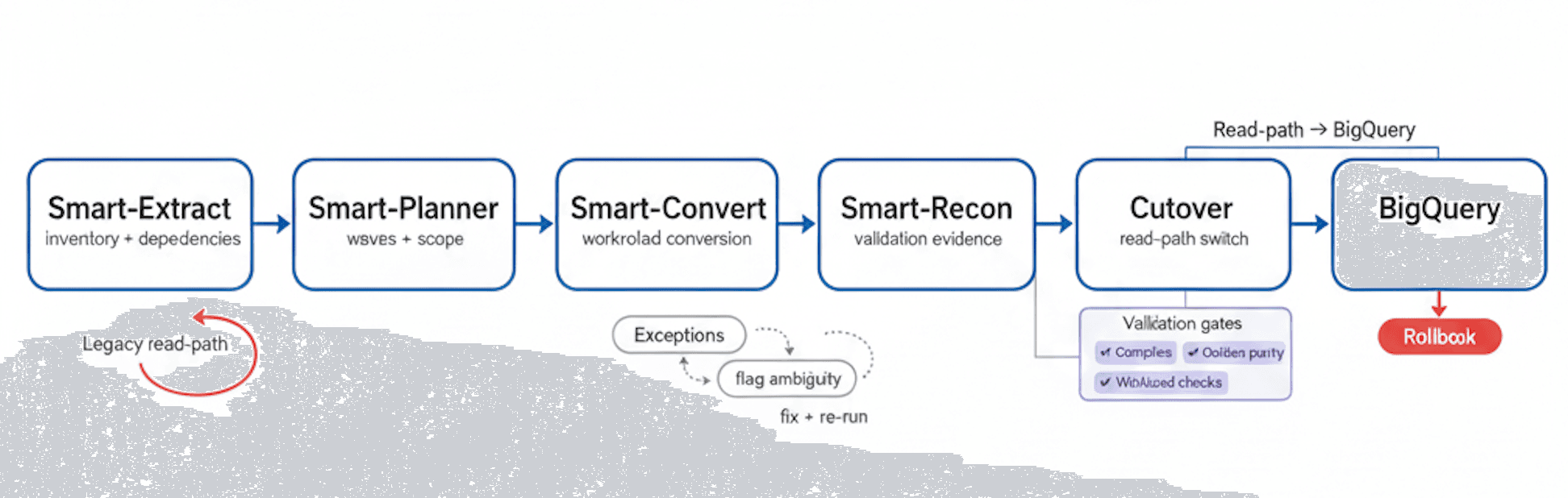
Migration Flow
Extract → Plan → Convert → Reconcile → Cutover to BigQuery, with exception handling, validation gates, and a rollback path
SQL & Workload Conversion Overview
Impala to BigQuery migration is not just “SQL translation.” The objective is to preserve business meaning while aligning to BigQuery’s execution model and cost structure. SmartMigrate converts what is deterministic, flags ambiguity, and structures the remaining work so engineering teams can resolve exceptions quickly.
At a high level, we handle DDL conversion (schemas, types, partition intent), query conversion (joins, windows, CTEs, subqueries), and a pragmatic UDF strategy that accounts for what cannot be ported directly. Every conversion step is paired with validation signals: compiler checks first, then semantic checks, then reconciliation.
What we automate vs. what we flag:
- Automated: common Impala SQL patterns into BigQuery SQL, routine DDL mapping, straightforward join/aggregation conversions, safe function rewrites.
- Flagged as “review required”: ambiguous implicit casts, complex window frames, NULL-sensitive logic, UDF/UDAF dependencies, and “data explosion” patterns.
- Manual by design: custom business UDF logic decisions, performance-sensitive query rewrites, and partition/clustering strategy finalization.
UDF strategy options (choose per workload):
- Rewrite logic into BigQuery SQL where feasible
- Replace with BigQuery-native capabilities (arrays/structs, analytic functions)
- Use remote UDFs selectively for complex business rules
- Precompute/reshape upstream to remove runtime complexity
Migration process: from inventory to cutover
- 01Inventory
Discovery & inventory
Identify Impala tables, queries, dependencies, SLAs, and critical golden outputs that define correctness.
- 02Cutover
Conversion plan
Define data type mapping decisions, workload waves, risk areas, and the cutover plan structure.
- 03Convert
Automated SQL translation + exception triage
Translate Impala SQL to BigQuery, classify exceptions, and produce a prioritized fix list.
- 04Cutover
Data movement strategy + cutover design
Choose batch and/or CDC patterns, define parallel run approach, and establish rollback criteria.
- 05Validate
Validation & reconciliation
Run row counts, aggregates, sampling diffs, and golden query parity checks; document variances and resolutions.
- 06Step
Performance optimization
Tune partitioning/clustering, materialization, and query patterns; reduce bytes scanned and stabilize concurrency.
- 07Cutover
Cutover + rollback readiness + monitoring
Execute cutover with canary gates, monitor SLAs, and keep a tested rollback path available until stability is proven.
Common failure modes
- Implicit CAST behaviorChanges in numeric and timestamp casting alter aggregates
- Partitioning assumptionsImpala partition logic does not map 1:1 to BigQuery pruning
- UDF dependenciesBusiness rules embedded in UDFs are not portable by default
- Explosion patternsUNNEST / cross-join patterns can cause cost and latency spikes
- Hidden BI couplingReports depend on undocumented query behavior.
Validation and reconciliation you can sign off on
In an Impala to BigQuery migration, success must be measurable. We validate correctness at two levels: first by ensuring translated SQL compiles and executes reliably, and then by proving that outputs match expected business meaning via reconciliation.
Validation is driven by pre-agreed thresholds and a defined set of golden queries and datasets. This makes sign-off objective: when reconciliation passes, cutover is a controlled decision; when it fails, you get a precise delta report that identifies where semantics or data type mapping needs adjustment.
Checks included (typical set):
- Row counts by table and by key partitions
- Null distribution and basic column profiling (min/max, distinct counts where appropriate)
- Checksums/hashes for stable subsets where feasible
- Aggregate comparisons by key dimensions (day, region, customer/product keys)
- Sampling diffs: top-N, edge partitions, and known corner cases
- Query result parity for golden queries (reports and KPI queries)
- Post-cutover SLA monitoring plan and dashboards (latency, bytes scanned, failure rates)
Performance optimization in BigQuery
- Partitioning strategy (ingestion-time and query-time)
- Align partition keys to dominant filters to improve pruning and reduce bytes scanned.
- Clustering on high-selectivity columns
- Improve performance for common predicates and joins when partitions alone are not sufficient.
- Rewrite explosion patterns
- Avoid cross joins and uncontrolled array expansion; use UNNEST carefully with filters early.
- Materialized views and summary tables
- Stabilize BI workloads and reduce repeated full-scan aggregations for high-traffic dashboards.
- Concurrency and slot usage planning
- Decide on on-demand vs slot reservations based on workload mix and required predictability.
- Cost hygiene via selectivity and pruning
- Encourage explicit column selection, predicate placement, and partition filters to control scan cost.
- Ingestion format and load patterns
- Standardize loads to minimize schema drift and avoid repeated backfills.
- Query plan observability
- Use query logs and INFORMATION_SCHEMA to monitor regressions and verify tuning outcomes.
- Join strategy tuning
- Pay attention to join cardinality and filter ordering to avoid large intermediate results.
Impala → BigQuery migration checklist
- Can you name the “parity contract” in writing?Do you have a signed-off definition of correctness (golden queries, thresholds, edge cases like DECIMAL/TIMESTAMP/timezone), before anyone translates a line of SQL?
- Do you have an answer for UDF/UDAFs that won’t blow up your timeline?For every UDF/UDAF and hidden BI logic dependency: who owns the rewrite decision, what’s the fallback, and how will you prevent “works in staging, wrong in prod”?
- Do you have a reconciliation harness that produces evidence, not anecdotes?Not “we spot-checked a few tables” — but repeatable row/aggregate/sample parity, delta reports, and a paper trail your auditors + business owners accept.
- Is your cutover plan rollback-safe under real concurrency and cost?Parallel run window, canary gates, rollback criteria, plus BigQuery cost/perf guardrails (bytes scanned, slot/concurrency behavior) that prevent a post-cutover cost incident.
- If the migration slips or results drift, who is accountable and how do you know where it broke?Do you have instrumentation that pinpoints failures to: type semantics, function differences, partition strategy, explosion patterns, or BI coupling — with a prioritized fix list?
Frequently asked questions
What are the biggest differences between Impala and BigQuery SQL?+
How do you handle DECIMAL and TIMESTAMP differences?+
What happens to partitioned tables from Impala?+
How do you validate results are correct after SQL translation?+
Do you support UDFs and custom functions?+
How do you estimate BigQuery cost after migration?+
Can we migrate with minimal downtime?+
Get a migration plan you can execute—with validation built in. We’ll inventory your Impala estate, convert representative workloads, surface risks in SQL translation and data type mapping, and define a validation and reconciliation approach tied to your SLAs. You’ll also receive a cutover plan with rollback criteria and performance optimization guidance for BigQuery.