Redshift → Snowflake migration
Move Redshift workloads (SQL, views, UDFs, stored procedures, Spectrum/external tables, and WLM-driven concurrency) to Snowflake with predictable conversion and verified parity. SmartMigrate makes semantic and performance differences explicit, produces reconciliation evidence you can sign off on, and gates cutover with rollback-ready criteria—so production outcomes are backed by proof, not optimism.
- Scope
- Query and schema conversion
- Semantic and type alignment
- Validation and cutover readiness
- Risk areas
- SQL dialect + function behavior differences
- Distribution/sort keys don’t carry over
- WLM vs warehouse concurrency
- Deliverables
- Prioritized execution plan
- Parity evidence and variance log
- Rollback-ready cutover criteria
Is this migration right for you?
- You have a mature Redshift estate with hundreds/thousands of queries and BI dependencies
- You rely on Spectrum/external tables and S3-driven ingestion patterns (COPY/UNLOAD)
- Performance and concurrency predictability matter for SLAs
- You require provable parity and reconciliation evidence before cutover
- You want Snowflake cost governance (credits) and workload isolation from day one
- You’re doing a simple one-time table copy with no semantic dependency on existing queries
- You don’t need reconciliation evidence or rollback guarantees
- There are no critical consumers depending on strict output parity
What breaks in a Redshift → Snowflake migration
- SQL dialect + function behavior differences
Redshift is Postgres-derived but has its own behavior around JSON/SUPER, date/time functions, string functions, NULL handling, and implicit casts. Snowflake is ANSI-leaning and has different type coercion rules. Edge cases surface as “same query, different KPI.”
- Distribution/sort keys don’t carry over
Redshift performance depends heavily on DISTKEY/SORTKEY, table design, and vacuum/analyze discipline. Snowflake abstracts distribution; performance becomes a function of micro-partition pruning, (selective) clustering, join strategy, and warehouse sizing.
- WLM vs warehouse concurrency
Redshift WLM queues, slots, and query priorities don’t map 1:1. In Snowflake, concurrency and latency are governed by virtual warehouses, auto-suspend/resume, and (optionally) multi-cluster scaling. Without workload isolation, BI bursts and batch windows fight each other.
- UNLOAD/COPY, Spectrum, and external-table patterns
Redshift pipelines often embed S3-centric UNLOAD/COPY patterns and Spectrum queries. These need a Snowflake-native execution plan (stages + COPY INTO, Snowpipe, external tables where appropriate) or operational workloads become fragile.
- Procedures/UDFs and orchestration glue
Stored procedures, UDFs, and scheduler glue (Airflow/Step Functions/dbt jobs) must be migrated with an execution plan—or pipelines fail post-cutover.
- Security + governance translation
IAM roles, KMS/S3 policies, and Redshift permissions map differently to Snowflake RBAC, warehouses, resource monitors, and data governance patterns. If you treat security as “later,” adoption stalls.
| Breakage | Mitigation |
|---|---|
SQL dialect + function behavior differences Redshift is Postgres-derived but has its own behavior around JSON/SUPER, date/time functions, string functions, NULL handling, and implicit casts. Snowflake is ANSI-leaning and has different type coercion rules. Edge cases surface as “same query, different KPI.” | Assess, rewrite where needed, then validate with parity checks. |
Distribution/sort keys don’t carry over Redshift performance depends heavily on DISTKEY/SORTKEY, table design, and vacuum/analyze discipline. Snowflake abstracts distribution; performance becomes a function of micro-partition pruning, (selective) clustering, join strategy, and warehouse sizing. | Assess, rewrite where needed, then validate with parity checks. |
WLM vs warehouse concurrency Redshift WLM queues, slots, and query priorities don’t map 1:1. In Snowflake, concurrency and latency are governed by virtual warehouses, auto-suspend/resume, and (optionally) multi-cluster scaling. Without workload isolation, BI bursts and batch windows fight each other. | Assess, rewrite where needed, then validate with parity checks. |
UNLOAD/COPY, Spectrum, and external-table patterns Redshift pipelines often embed S3-centric UNLOAD/COPY patterns and Spectrum queries. These need a Snowflake-native execution plan (stages + COPY INTO, Snowpipe, external tables where appropriate) or operational workloads become fragile. | Assess, rewrite where needed, then validate with parity checks. |
Procedures/UDFs and orchestration glue Stored procedures, UDFs, and scheduler glue (Airflow/Step Functions/dbt jobs) must be migrated with an execution plan—or pipelines fail post-cutover. | Assess, rewrite where needed, then validate with parity checks. |
Security + governance translation IAM roles, KMS/S3 policies, and Redshift permissions map differently to Snowflake RBAC, warehouses, resource monitors, and data governance patterns. If you treat security as “later,” adoption stalls. | Assess, rewrite where needed, then validate with parity checks. |
Migration Flow
Extract → Plan → Convert → Reconcile → Cutover to Snowflake, with exception handling, validation gates, and a rollback path
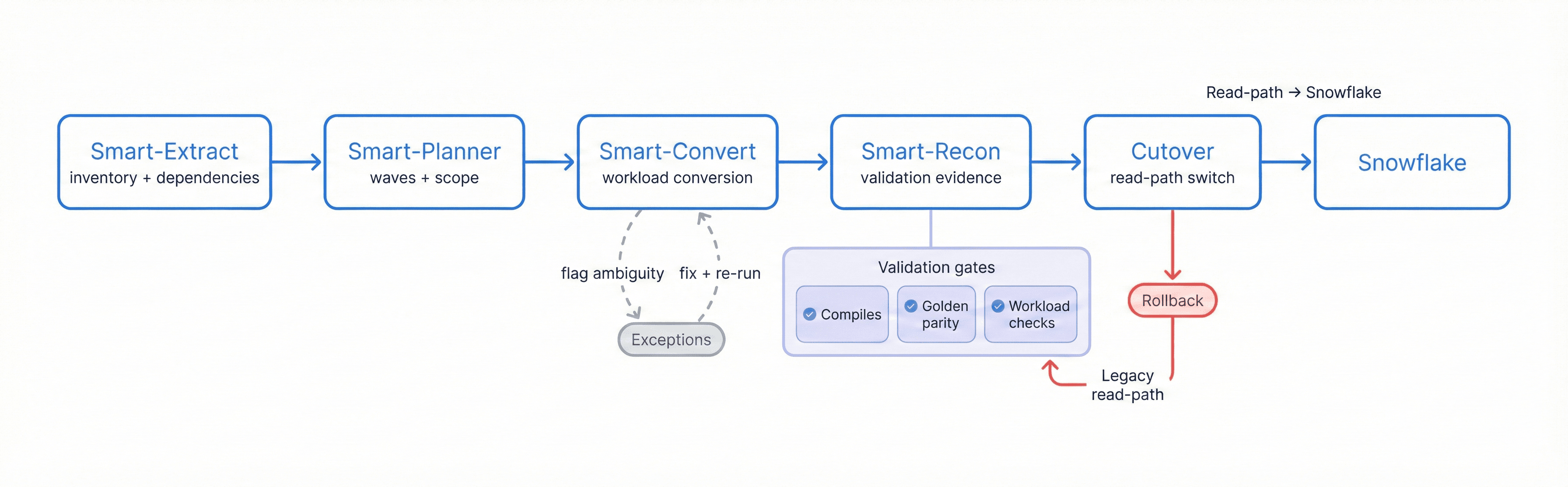
SQL & Workload Conversion Overview
Redshift → Snowflake migration is not just “SQL translation.” The objective is to preserve business meaning while aligning to Snowflake’s execution model, governance patterns, and operational cost controls. SmartMigrate converts what is deterministic, flags ambiguity, and structures the remaining work so engineering teams can resolve exceptions quickly.
What we automate vs. what we flag:
- Automated: Common Redshift SQL patterns into Snowflake SQL, routine DDL mapping, straightforward join/aggregation conversions, safe function rewrites, baseline view conversion, and standard unload/load pattern rewrites where deterministic.
- Flagged as “review required”: Implicit casts and NULL-sensitive logic, timestamp/timezone behavior, JSON/SUPER and semi-structured patterns, Spectrum/external-table dependencies, procedural SQL/UDFs, and performance-sensitive query shapes.
- Manual by design: Final warehouse strategy (size, auto-suspend/resume, multi-cluster), clustering/materialization strategy for hot workloads, procedure/UDF execution design, and workload isolation strategy (BI vs batch vs ELT).
Common failure modes
- Type coercion and timestamp driftDifferences in numeric precision, string-to-number casting, and timestamp/timezone behavior silently change aggregates and join matches.
- DISTKEY/SORTKEY assumptions carried overRedshift physical tuning is treated as “schema,” and Snowflake performance degrades because pruning/clustering/warehouse sizing weren’t planned.
- WLM mismatch causes SLA surprisesRedshift queue/slot expectations don’t map; Snowflake needs explicit warehouse isolation and concurrency strategy.
- Spectrum and external dependencies breakQueries and pipelines relying on Spectrum/external tables lose semantics or performance unless re-homed (Snowflake external tables, stages, or ingestion redesign).
- COPY/UNLOAD patterns become fragileRedshift-centric unload/load scripts aren’t re-homed cleanly (stages/COPY INTO/Snowpipe), causing slow loads, retries, and brittle backfills.
- Procedure/UDF gapsStored procedures and UDFs are deferred, and operational workloads break after cutover.
- Credit model whiplashWorkloads tuned for Redshift become expensive in Snowflake due to warehouse sizing, concurrency bursts, or long-running transforms without auto-suspend discipline
- Security translation missedRBAC/warehouse permissions and resource monitors aren’t designed up front; teams can’t safely adopt the new platform.
Validation and reconciliation you can sign off on
In a Redshift → Snowflake migration, success must be measurable. We validate correctness in layers: first ensuring translated workloads compile and execute reliably, then proving that outputs match expected business meaning via reconciliation.
Validation is driven by pre-agreed thresholds and a defined set of golden queries and datasets. This makes sign-off objective: when reconciliation passes, cutover is controlled; when it fails, you get a precise delta report that identifies where semantics, type mapping, or query logic needs adjustment.
Checks included (typical set):
- Row counts by table and key partitions where applicable
- Null distribution + basic profiling (min/max, distinct counts where appropriate)
- Checksums/hashes for stable subsets where feasible
- Aggregate comparisons by key dimensions (day, region, customer/product keys)
- Sampling diffs: top-N, edge partitions, known corner cases
- Query result parity for golden queries (reports and KPI queries)
- Post-cutover SLA monitoring plan (latency, credit burn, failures, concurrency/warehouse saturation)
Performance optimization in Snowflake
- Warehouse sizing and isolation:
- Right-size warehouses per workload class; isolate BI from ELT/batch to avoid contention.
- Auto-suspend / auto-resume discipline:
- Prevent idle burn; structure pipelines so compute is on only when needed.
- Pruning-aware table design:
- Organize data (ingestion patterns + filter keys) to maximize micro-partition pruning.
- Selective clustering (when it pays):
- Apply clustering keys only to tables where pruning materially improves repeated hot queries.
- Materialized views and summary tables:
- Stabilize BI workloads and reduce repeated heavy transforms.
- Concurrency controls:
- Use separate warehouses, resource monitors, and (optionally) multi-cluster scaling for predictable peak behavior.
- Query plan observability:
- Use query history/profiles to detect regressions and validate tuning outcomes.
- Join strategy tuning:
- Reduce large intermediates by managing join cardinality, filters, and spill-prone patterns.
Redshift → Snowflake migration checklist
- Parity contract existsDo you have signed-off golden queries/reports + thresholds (including casting/time behavior and NULL edge cases) before conversion starts?
- External + ingestion dependencies are in scopeHave you inventoried Spectrum/external-table usage and unload/load pipelines (COPY/UNLOAD), and decided Snowflake equivalents (stages, COPY INTO, Snowpipe)?
- Procedures/UDFs and orchestration are plannedDo you have a plan to translate or re-home stored procedures/UDFs and scheduler glue with operational parity?
- Warehouse and concurrency strategy is explicitHave you defined warehouse sizing, auto-suspend/resume, workload isolation (BI vs ELT), and whether multi-cluster is needed for peak concurrency?
- Cutover is rollback-safe under real concurrency and costParallel run + canary gates + rollback criteria + Snowflake guardrails (credits, warehouse saturation, query latency, failure rates) are ready.
Frequently asked questions
What are the biggest differences between Redshift and Snowflake SQL? +
How do you handle casting, NULL behavior, and timestamp edge cases? +
What happens to Spectrum, external tables, and S3-based pipelines?+
How do you validate results are correct after SQL translation? +
How do you estimate Snowflake cost after migration? +
Can we migrate with minimal downtime? +
Get a migration plan you can execute—with validation built in. We’ll inventory your Redshift estate (including views, procedures/UDFs, Spectrum/external-table usage, and unload/load pipelines), convert representative workloads, surface risks in SQL translation and type mapping, and define a validation and reconciliation approach tied to your SLAs. You’ll also receive a cutover plan with rollback criteria and performance optimization guidance for Snowflake.