Snowflake → BigQuery migration
Move Snowflake workloads (SQL, VARIANT/JSON, Streams/Tasks, stored procedures, masking policies, and BI semantics) to BigQuery with predictable conversion and verified parity. SmartMigrate makes semantic differences explicit, produces reconciliation evidence you can sign off on, and gates cutover with rollback-ready criteria—so you don’t discover “almost correct” in production
- Scope
- Query and schema conversion
- Semantic and type alignment
- Validation and cutover readiness
- Risk areas
- Semi-structured semantics (VARIANT / FLATTEN)
- Time + casting drift
- Tasks, Streams, Procedures, and orchestration reality
- Deliverables
- Prioritized execution plan
- Parity evidence and variance log
- Rollback-ready cutover criteria
Is this migration right for you?
- You have hundreds or thousands of Snowflake queries and BI dependencies
- You use VARIANT/JSON heavily (FLATTEN patterns, nested payloads)
- You rely on Streams/Tasks/procedures for operational pipelines
- You need provable parity, reconciliation evidence, and rollback-ready cutover
- You want cost and performance that’s governed—not guessed
- You’re doing a one-time export/import with no semantic dependency
- You don’t need reconciliation evidence or rollback guarantees
- There are no critical reports or consumers requiring strict output parity
What breaks in a Snowflake → BigQuery migration
- Semi-structured semantics (VARIANT / FLATTEN)
VARIANT + FLATTEN patterns don’t map 1:1 to BigQuery JSON/STRUCT/ARRAY + UNNEST. The wrong modeling choice creates either wrong results or runaway row expansion.
- Time + casting drift
NUMBER/DECIMAL precision, implicit casts, and timestamp/timezone handling can subtly change joins, aggregates, and KPI outputs.
- Tasks, Streams, Procedures, and orchestration reality
A Snowflake estate isn’t “just tables + queries.” Tasks, Streams, procedures, and operational dependencies must be re-homed with an execution strategy (not deferred until the end).
- Security and policy parity
RBAC, masking/row access policies, and governance controls require explicit mapping. Missing a policy is a production incident, not a rounding error.
- Cost model mismatch under concurrency
Snowflake warehouse scaling vs BigQuery bytes-scanned + slots/reservations changes the economics of repeated BI and ELT patterns—especially when semi-structured data is involved
- Hidden BI coupling
Dashboards can depend on rounding, ordering, NULL behavior, and time semantics that no one wrote down. If you don’t lock a “parity contract,” you will argue with the business at cutover.
| Breakage | Mitigation |
|---|---|
Semi-structured semantics (VARIANT / FLATTEN) VARIANT + FLATTEN patterns don’t map 1:1 to BigQuery JSON/STRUCT/ARRAY + UNNEST. The wrong modeling choice creates either wrong results or runaway row expansion. | Assess, rewrite where needed, then validate with parity checks. |
Time + casting drift NUMBER/DECIMAL precision, implicit casts, and timestamp/timezone handling can subtly change joins, aggregates, and KPI outputs. | Assess, rewrite where needed, then validate with parity checks. |
Tasks, Streams, Procedures, and orchestration reality A Snowflake estate isn’t “just tables + queries.” Tasks, Streams, procedures, and operational dependencies must be re-homed with an execution strategy (not deferred until the end). | Assess, rewrite where needed, then validate with parity checks. |
Security and policy parity RBAC, masking/row access policies, and governance controls require explicit mapping. Missing a policy is a production incident, not a rounding error. | Assess, rewrite where needed, then validate with parity checks. |
Cost model mismatch under concurrency Snowflake warehouse scaling vs BigQuery bytes-scanned + slots/reservations changes the economics of repeated BI and ELT patterns—especially when semi-structured data is involved | Assess, rewrite where needed, then validate with parity checks. |
Hidden BI coupling Dashboards can depend on rounding, ordering, NULL behavior, and time semantics that no one wrote down. If you don’t lock a “parity contract,” you will argue with the business at cutover. | Assess, rewrite where needed, then validate with parity checks. |
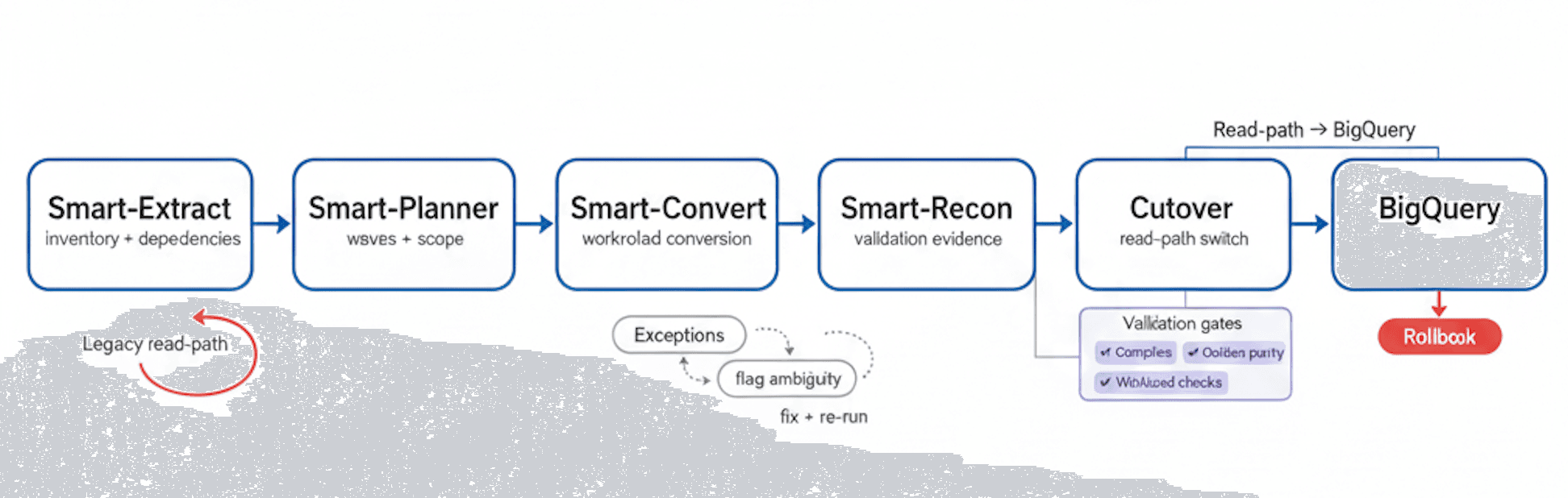
Migration Flow
Extract → Plan → Convert → Reconcile → Cutover to BigQuery, with exception handling, validation gates, and a rollback path
Common failure modes (Snowflake → BigQuery)
- Implicit CAST driftSilent type coercions change aggregates and join matches, especially around NUMBER/DECIMAL and TIMESTAMP.
- VARIANT expansion explosionFLATTEN-to-UNNEST rewrites blow up row counts, driving cost spikes and unstable latency.
- Timezone semantics mismatchTimestamp parsing and timezone assumptions shift daily/weekly rollups and KPI cut lines.
- Procedural workload gapsStreams/Tasks/procedures get deferred, and critical schedules break right after cutover.
- Policy parity breakMasking/row access rules don’t translate cleanly, causing access incidents or compliance gaps.
- Cost model whiplash“Same query” becomes expensive due to bytes-scanned patterns, clustering/partition misses, or repeated BI scans.
- Hidden BI couplingDashboards depend on undocumented rounding/NULL/order behavior and fail parity under executive scrutiny.
- Environment workflow lossClone/time-travel driven dev/test workflows disappear, slowing delivery and increasing cutover risk.
- Incremental logic divergenceMERGE/upsert and incremental ELT patterns behave differently, creating slowly accumulating drift.
- Externalization assumptionsStage/file patterns and ingestion conventions don’t carry over, breaking pipelines and backfills.
Validation and reconciliation you can sign off on
In a Snowflake → BigQuery migration, success must be measurable. We validate correctness in layers: first ensuring translated workloads compile and execute reliably, then proving outputs match expected business meaning via reconciliation.
Validation is driven by pre-agreed thresholds and a defined set of golden queries and datasets. This makes sign-off objective: when reconciliation passes, cutover is controlled; when it fails, you get a precise delta report that points to the cause (casting, function behavior, JSON expansion, policy parity, or procedural gaps).
Checks included (typical set):
- Row counts by table (and key partitions where applicable)
- Null distribution + basic profiling (min/max, distinct counts where appropriate)
- Aggregate parity by key dimensions (day, region, customer/product keys)
- Sampling diffs (edge partitions + known corner cases)
- Golden query / golden report result parity
- Post-cutover monitoring plan (latency, bytes scanned, failures, concurrency/slots)
Performance optimization in BigQuery
- Partitioning strategy:
- Align partitions to dominant filters to reduce bytes scanned
- Clustering:
- Improve pruning and join performance when partitions aren’t enough
- Control expansion:
- Avoid uncontrolled UNNEST; filter early; materialize stable shapes
- Materialization:
- Use summary tables/materialized views for repeated BI workloads
- Slots/concurrency plan:
- Decide on on-demand vs reservations for predictable performance
- Cost hygiene:
- Selectivity, predicate placement, and column selection to control scans
- Observability:
- Use query logs + INFORMATION_SCHEMA to track regressions
Snowflake → BigQuery migration checklist
- Parity contract existsDo you have signed-off golden queries/reports + thresholds (including timezone + semi-structured edge cases) before conversion starts?
- Semi-structured modeling is a deliberate decisionDo you know how VARIANT will be represented (JSON vs STRUCT/ARRAY), and how expansion will be controlled and tested?
- Procedural + operational dependencies are not “later”Do you have a plan for Streams/Tasks/procedures and orchestration that preserves schedules and operational behavior?
- Security parity is provableCan you demonstrate policy equivalence (roles, masking, row/column rules) with audit-style checks?
- Cutover is rollback-safe under real cost and concurrencyParallel run + canary gates + rollback criteria + BigQuery cost/perf guardrails (bytes scanned, slots, latency) are ready.
Frequently asked questions
What are the biggest differences between Snowflake and BigQuery?+
How do you handle NUMBER/DECIMAL and TIMESTAMP differences?+
What happens to VARIANT and FLATTEN patterns?+
Do you support Streams/Tasks/procedures?+
How do you validate correctness?+
How do you estimate BigQuery cost post-migration?+
Can we migrate with minimal downtime?+
Get a migration plan you can execute—with validation built in. We’ll inventory your Snowflake estate (including VARIANT + Streams/Tasks/procedures + security policies), convert representative workloads, surface risks in SQL translation and modeling choices, and define a validation and reconciliation approach tied to your SLAs. You’ll also receive a cutover plan with rollback criteria and performance/cost